s3-kennisbank
De rol van een analist bij gebruik van AI
In dit onderdeel gaan we in op de rol van een analist bij het gebruik van AI en LLMs (Large Language Models) bij het ontwikkelen van software. We bespreken wat vibe coding is, waarom het relevant is, en hoe een analist kan bijdragen aan het succes van een project dat gebruik maakt van AI.
What is vibe coding?
Er is veel nog onduidelijk over de toekomst van AI en LLMs, maar een van de kreten die veel gebruikt wordt is 'vibe coding'. Sommigen zijn fel tegenstander en vinden het belachelijk anderen denken dat het de toekomst is. Veel van de tegengestelde meningen komen voort uit de interpretatie van de kreet 'vibe coding'. Dus wat is het?
Mogelijke definities
- Doing most of the Work via plain English
- Ignoring the code entirely and only use prompting
- Non developers writing code using AI
- Using auto complete (tab) in your IDE
Een serieuze software developer vindt wellicht dat 3) een belachelijk idee is, maar gebruikt 4) wel. Dit zouden we in onderstaand diagram uit kunnen zetten:
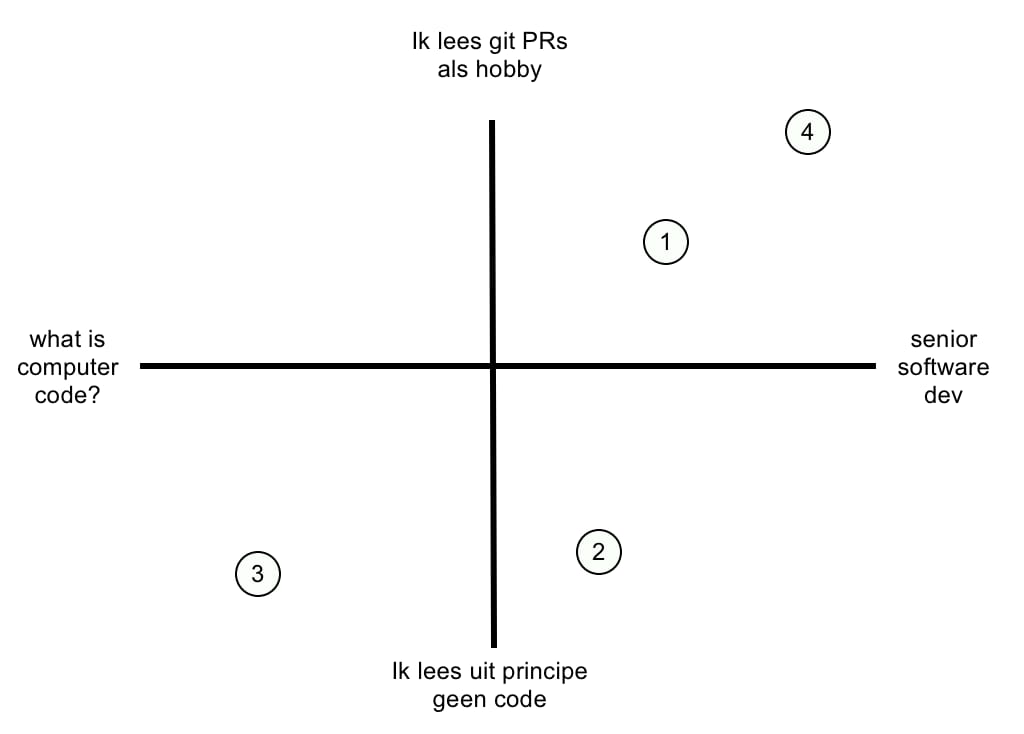
Bij 1) is het belangrijke woord 'most'. We hebben hier te maken met iemand die wel degelijk zelf code kan maken, maar zo veel mogelijk gebruik maakt van een LLM om zo veel mogelijk code te laten genereren.
Bij 2) is een developer aan de slag die geen zin (of geen tijd) heeft om de code zelf te genereren. Hij zou het wellicht wel kunnen, maar heeft er gewoon geen interesse in.
Bij 3) gaat het om iemand die weinig of geen verstand heeft van het genereren van code en daar ook geen enkele interesse in heeft.
Bij 4) zien we een ervaren developer, die primair zijn eigen code schrijft, maar wel gebruik maakt van een LLM om het proces te versnellen.
Waarom vibe coding?
Zoals je hierboven kan zien is daar geen simpel antwoord op te geven. Complete applicaties laten genereren door mensen die geen enkel verstand van code hebben lijkt vooralsnog weinig succesvol (en in ieder geval weinig betrouwbaar). Maar met verstand van zaken en strategisch gebruikt kan het de productiviteit van een developer aanzienlijk verhogen.
We doen al jaren aan vibe coding...
Vibe coding kan code opleveren waarvan we niet precies weten hoe het werkt. We hebben het niet zelf geschreven, wel gedefinieerd wat het moet doen en er zelfs misschien tests voor geschreven, maar niet de code zelf.
Wat is nu precies het verschil met het gebruik maken van een package of een library? Ook daarbij gebruiken we code die we niet zelf geschreven hebben. Door een bepaalde library te gebruiken hebben we alleen gedefinieerd wat er moet gebeuren, maar we maken ons niet druk om hoe die code er precies uitziet of hoe het werkt.
Het enige verschil is dat bij vibe coding de code heel specifiek gegenereerd wordt voor jouw specificaties terwijl de meeste libraries ongeveer (met net niet helemaal) doen wat je zou willen.
Not all code is created equal
Over het algemeen gebruik je libraries niet voor het essentiële deel van je applicatie, maar voor al die zaken die 'ook moeten gebeuren'. Stel je moet de input van een gebruiker opschonen door er bijvoorbeeld alle dubbele spaties uit te halen. Dit kan je prima doen met een RegEx (zoek maar een op wat dat is), je kan ook op zoek gaan naar een library die dit soort code heeft, maar je kan het ook laten genereren door een LLM.
Je zal als analist dus moeten gaan identificeren welke functionaliteit je prima door een LLM kan laten genereren en welke code je door het team laat maken (omdat daar bijvoorbeeld veel meer kennis van het klantdomein voor nodig is). Dat zal een belangrijke competentie worden in de toekomst.
Kwaliteit van door LLMs gegenereerde code
LLMs worden in rap tempo beter en leveren ook betere code op. Toch heeft de analist een rol bij het garanderen van die kwaliteit. Als je een LLM ziet als een extra programmeur, dan zal je deze, net als elke andere developer, goed moeten instrueren over wat er gemaakt moet worden en hoe dat gemaakt moet worden.
Als je een LLM alleen maar (een vage) omschrijving geeft van de bedoeling van een stuk code, dat zal deze (eigenlijk net als een mens) de ontbrekende stukjes informatie er zelf bij gaan verzinnen. Het is dus zaak om zo duidelijk mogelijk te zijn. Daar speelt de analist/architect een grote rol.
Je zal niet alleen de bedoeling van een stuk code heel duidelijk moeten maken (door bv een user story), maar ook de gekozen architectuur heel exact moeten toelichten. Welke patronen moeten er gebruikt worden? Wat moet in welke file staan. Hoe ga je binnen het project om met bv de SOLID-principes? Hoe beter je dit specificeert, hoe beter de code van de LLM zal zijn.
Verder kan je natuurlijk de verschillende test mogelijkheden ook gebruiken om de LLM te sturen. En denk hierbij niet alleen aan de unittest (ook belangrijk), maar ook aan de linter, en aan wat je eerder bij het analistgilde geleerd hebt (BDD).
Beperking van LLMs
LLMs worden getraind op een grote hoeveelheid data. Maar die data is niet altijd up-to-date. Zo is de kennis van GPT-4 bijvoorbeeld beperkt tot ergens in 2021. Dat betekent dat als je een LLM vraagt om code te genereren die gebruik maakt van een library die na die tijd is uitgekomen, dat de LLM daar geen kennis van heeft.
Daarnaast is de kennis van een LLM heel generiek. Het heeft geen kennis van jouw specifieke project, de architectuur die je gebruikt, de patronen die je hanteert, de manier waarop jullie met data omgaan, etc. Je zal een LLM dus nog veel precieser moeten instrueren dan een menselijke developer die al een tijdje in het team zit. De LLM heeft niet hetzelfde referentiekader als een menselijke developer in jou team.
Een uitdaging voor de analist/architect is dus om de instructies voor een LLM zo te formuleren dat deze precies genoeg zijn om de code te genereren die je wilt hebben. Hiermee kan je direct je vaardigheden als analist/architect verbeteren.
Werken met LLMs
Er zijn helaas nog geen standaarden voor het instrueren van LLMs met betrekking tot het genereren van code. Er zijn veel initiatieven, maar het gedrag van LLMs verandert per release eigenlijk nog teveel om hier iets over vast te leggen.
Maar wat in ieder geval goed werkt is markdown. LLMs kunnen markdown prima lezen (en genereren). Dus je hebt al een mooie stap gemaakt als je de architectuur volledig en nauwkeurig in markdown hebt (iets dat je natuurlijk al gedaan hebt als projectdocumentatie, toch?).
Hieronder geven we een aantal mogelijkheden om een LLM te instrueren:
AGENTS.md
De meest eenvoudige methode is in een markdown bestand een aantal regels op te nemen die de LLM moet volgen. Er is een door de open source gemeenschap gedragen voorstel om dit bestand AGENTS.md te noemen. Meer informatie hierover is te vinden op hun website.
Een voorbeeld van zo'n bestand is hieronder weergegeven:
# Sample AGENTS.md file
## Dev environment tips
- Use `pnpm dlx turbo run where <project_name>` to jump to a package instead of scanning with `ls`.
- Run `pnpm install --filter <project_name>` to add the package to your workspace so Vite, ESLint, and TypeScript can see it.
- Use `pnpm create vite@latest <project_name> -- --template react-ts` to spin up a new React + Vite package with TypeScript checks ready.
- Check the name field inside each package's package.json to confirm the right name—skip the top-level one.
## Testing instructions
- Find the CI plan in the .github/workflows folder.
- Run `pnpm turbo run test --filter <project_name>` to run every check defined for that package.
- From the package root you can just call `pnpm test`. The commit should pass all tests before you merge.
- To focus on one step, add the Vitest pattern: `pnpm vitest run -t "<test name>"`.
- Fix any test or type errors until the whole suite is green.
- After moving files or changing imports, run `pnpm lint --filter <project_name>` to be sure ESLint and TypeScript rules still pass.
- Add or update tests for the code you change, even if nobody asked.
## PR instructions
- Title format: [<project_name>] <Title>
- Always run `pnpm lint` and `pnpm test` before committing.
Naast de naam AGENTS.md en het gegeven dat het een markdown bestand is, zijn er geen regels voor de inhoud. Je kan dus zelf bepalen wat je hier in zet. Het is redelijk voor de hand liggend om hier de architectuur, de gebruikte patronen en de test strategie in op te nemen. Maar je kan hier ook andere zaken in opnemen die je belangrijk vindt. Als analist/architect kan je hier dus een belangrijke rol spelen.
Denk bijvoorbeeld aan:
- Architectuur (definieer de gewenste bouwstenen, hun verantwoordelijkheden en interacties, de lagen, etc)
- Patronen (welke patronen moeten er gebruikt worden, hoe moeten deze toegepast worden, etc)
- Stijl (hoe moet de code er uit zien, welke conventies moeten er gevolgd worden, etc)
- Test strategie (welke tests moeten er geschreven worden, hoe moeten deze geschreven worden, etc)
- Security (welke security maatregelen moeten er genomen worden, hoe moeten deze toegepast worden, etc)
De User Stories zullen zeer volledig moeten zijn, maar je kan in dit bestand ook nog extra eisen opnemen die voor elke user story gelden. Je werkt natuurlijk al met een Definition of Done (DoD). Je kan deze DoD ook in dit bestand opnemen. Zo zorg je er voor dat de LLM precies weet wat er van hem verwacht wordt. Neem links op naar wireframes, mockups, designs, etc. Zorg er voor dat de LLM precies weet wat er van hem verwacht wordt.
Eigenlijk niets anders als wat je normaal gesproken ook doet (zou moeten doen) als analist/architect, maar dan nu in een vorm die een LLM kan begrijpen.
TODO: OEFENING TOEVOEGEN VOOR HET WERKEN MET AGENTS.md
Vector stores
Een andere manier om context te bieden aan een LLM is door gebruik te maken van een vector store. Dit is een database waarin je documenten kan opslaan die de LLM kan gebruiken als context bij het genereren van code.
Een vector store werkt door documenten om te zetten in vectoren (getallenreeksen) die de betekenis van de tekst representeren. Deze vectoren worden vervolgens opgeslagen in een database die snel kan zoeken op basis van gelijkenis. Dit is in de basis hetzelfde als hoe een zoekmachine werkt.
Er zijn verschillende vector stores beschikbaar, zowel open source als commercieel. Enkele voorbeelden zijn Pinecone, Weaviate, en FAISS (open source). Als je met openAI (ChatGPT) werkt, dan kan je ook gebruik maken van hun ingebouwde vector store. Je opload files (bv in markdown) en deze worden automatisch omgezet in vectoren en opgeslagen. Bij de prompt kan je dan aangeven dat de LLM deze files als context moet gebruiken.
Wat is dan een RAG ( Retrieval Augmented Generation) model? Dit is een model dat gebruik maakt van een vector store om context te bieden aan een LLM. Het werkt door eerst de relevante documenten op te halen uit de vector store op basis van de input prompt. Deze documenten worden vervolgens gebruikt als extra context bij het genereren van de output door de LLM.
Vector stores zijn vooral handig als je veel documenten hebt die je wilt gebruiken als context voor de LLM. Bijvoorbeeld als je een grote hoeveelheid documentatie hebt die je wilt gebruiken om code te genereren. Het wordt minder gebruikt voor het genereren van code, maar meer voor het beantwoorden van vragen op basis van een grote hoeveelheid documenten.
Het is interessant om te kijken of je m.b.v. vector stores de applicatie die je aan het bouwen ben kan voorzien van klant/bedijfs specifieke kennis. Maak een vector store aan met alle relevante documentatie (bv in markdown) en doe requests aan de LLM waarbij je aangeeft dat deze documentatie als context moet gebruiken. Zo kan je een applicatie bouwen die gebruik maakt van een LLM, maar die ook specifieke kennis heeft over jouw klant/bedrijf.
Stel je wil een spel maken waarbij de LLM de rol van Game Master (GM) op zich neemt. Je kan dan een vector store maken met alle relevante informatie over het spel, de wereld, de personages, etc. De LLM kan dan deze informatie gebruiken om het spel te leiden en de spelers te begeleiden.
Onderstaande code laat zien hoe je een conversatie kan starten en voortzetten met gebruik van een vector store in TypeScript met de OpenAI API:
// Start the conversation
async startConversation(topic: string, message: string = ""): Promise<string> {
this.conversation = await this.client.conversations.create({
metadata: { topic: topic },
items: [
{ type: "message", role: "system", content: message }
],
});
return this.conversation.id;
}
// Continue the conversation using a vector store
async continueConversation(message: string, conversationId: string) {
const response = await this.client.responses.create({
conversation: conversationId,
model: this.model,
input: message,
tools: [
{
type: "file_search",
vector_store_ids: ["YOUR_VECTOR_STORE_ID"],
}
]
});
return response.output_text;
}
Tool calling
Een andere manier om context te bieden aan een LLM is door gebruik te maken van tool calling. Dit is een manier om de LLM te instrueren om bepaalde taken uit te voeren door gebruik te maken van externe tools.
Bij tool calling definieer je een aantal tools die de LLM kan gebruiken. Dit kunnen API's zijn, maar ook functies die je zelf hebt geschreven. De LLM kan deze tools aanroepen om bepaalde taken uit te voeren. Op deze manier kan je dynamische data vanuit je applicatie aanbieden aan de LLM.
Denk bijvoorbeeld aan een spel. De spelregels zijn statisch en kan je prima via bv een vector store aanbieden. Maar de status van het spel is dynamisch en verandert continu. Je kan de LLM niet steeds de volledige status van het spel aanbieden, dat wordt veel te groot. Maar je kan de LLM wel een tool aanbieden die de status van het spel kan opvragen. De LLM kan deze tool aanroepen om de huidige status van het spel op te vragen en deze gebruiken om het spel te leiden.
Wat een belangrijk verschil met een MCP server is dat je bij tool calling zelf de tools moet definiëren en implementeren. De LLM vraagt aan jou applicatie om een tool functie aan te roepen en het resultaat aan de LLM terug te geven. Bij een MCP server gaat de LLM zelf naar de MCP server om de context op te halen.
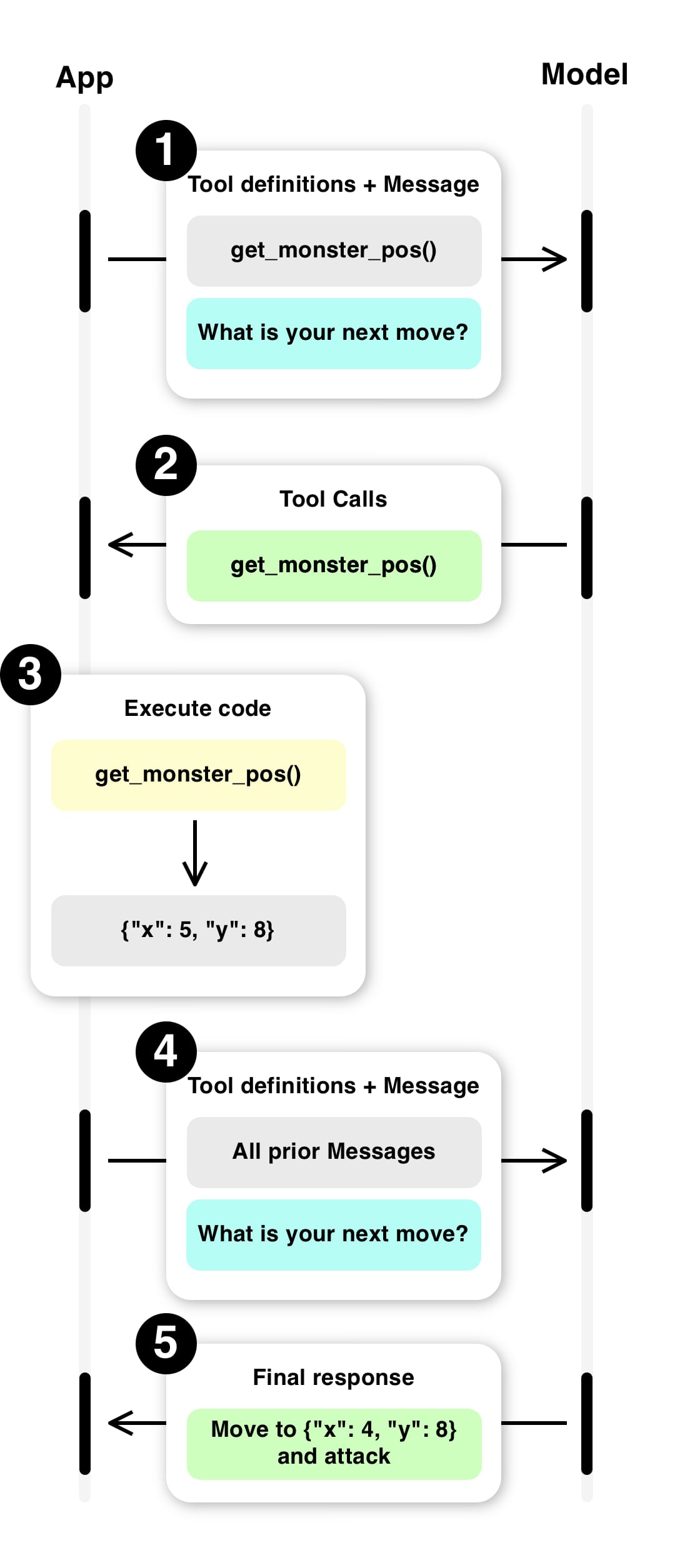
Documentatie over function calling
MCP Server
Een derde manier om context te bieden aan een LLM is door gebruik te maken van een MCP (Model Control Plane) server. Dit is een server die via het Model Context Protocol (MCP) communiceert met een LLM en die context kan bieden aan de LLM en de LLM in staat stelt om acties te ondernemen.
Een MCP server kan veel meer dan een vector store. Je kan er ook logica in opnemen om de output van de LLM te filteren, om meerdere LLMs te combineren, om de LLM te monitoren, etc. Je kan met MCPs hele workflows bouwen waarin de LLM een onderdeel is.
Technische informatie over MCPs
Er zijn ondertussen al verschillende open source MCP servers beschikbaar. Een lijst hiervan is te vinden op MCP Market
Voor het gebruiken van MCP server in VSCode is er een extensie beschikbaar: MCP for VSCode en is er documentatie beschikbaar op Use MCP servers in VS Code
Ook voor Intellij is er een extensie beschikbaar: MCP server en is er documentatie beschikbaar op Use MCP servers in IntelliJ
Spec driven development
Spec Kit maakt jouw specificatie het middelpunt van je ontwikkelproces. In plaats van een specificatie te schrijven en deze vervolgens te negeren, stuurt de specificatie de implementatie, checklists en taakverdeling aan. Jouw primaire rol is sturen; de code-agent doet het grootste deel van het schrijfwerk. Het is een soort van AGENTS.md, maar dan veel uitgebreider en met meer mogelijkheden.
Het proces werkt als volgt:
- Specify:
- Geef een high-level specificatie van wat je wilt bouwen.
- Plan:
- Nu wordt het technisch. In deze fase geef je de code-agent jouw gewenste stack, architectuur en randvoorwaarden, en genereert de code-agent een uitgebreid technisch plan.
- Tasks:
- De code-agent neemt de specificatie en het plan en verdeelt deze in daadwerkelijk uit te voeren taken. Hij genereert kleine, goed te beoordelen stukjes werk die elk een specifiek deel van het probleem oplossen.
- Implementation:
- Jouw code-agent pakt de taken één voor één op (of parallel, waar mogelijk). Maar wat hier anders is: in plaats van het beoordelen van enorme code-dumps van duizenden regels, beoordeel jij als ontwikkelaar gerichte wijzigingen die specifieke problemen oplossen.
Next steps
In het volgende deel gaan we dieper in op de verschillende technieken die je als analist/architect kan gebruiken om een LLM te instrueren.